Wiener Filter¶
nussl’s implementation just wraps norbert: https://sigsep.github.io/norbert/.
Wiener, Norbert. Extrapolation, interpolation, and smoothing of stationary time series. The MIT press, 1964.
Uhlich and M. Porcu and F. Giron and M. Enenkl and T. Kemp and N. Takahashi and Y. Mitsufuji, “Improving music source separation based on deep neural networks through data augmentation and network blending.” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017.
Nugraha and A. Liutkus and E. Vincent. “Multichannel audio source separation with deep neural networks.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 24.9 (2016): 1652-1664.
Nugraha and A. Liutkus and E. Vincent. “Multichannel music separation with deep neural networks.” 2016 24th European Signal Processing Conference (EUSIPCO). IEEE, 2016.
Liutkus and R. Badeau and G. Richard “Kernel additive models for source separation.” IEEE Transactions on Signal Processing 62.16 (2014): 4298-4310.
@book{wiener1964extrapolation,
title={Extrapolation, interpolation, and smoothing of stationary time series},
author={Wiener, Norbert},
year={1964},
publisher={The MIT press}
}
@inproceedings{uhlich2017improving,
title={Improving music source separation based on deep neural networks through data augmentation and network blending},
author={Uhlich, Stefan and Porcu, Marcello and Giron, Franck and Enenkl, Michael and Kemp, Thomas and Takahashi, Naoya and Mitsufuji, Yuki},
booktitle={2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={261--265},
year={2017},
organization={IEEE}
}
@article{nugraha2016multichannel,
title={Multichannel audio source separation with deep neural networks},
author={Nugraha, Aditya Arie and Liutkus, Antoine and Vincent, Emmanuel},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
volume={24},
number={9},
pages={1652--1664},
year={2016},
publisher={IEEE}
}
@inproceedings{nugraha2016multichannel,
title={Multichannel music separation with deep neural networks},
author={Nugraha, Aditya Arie and Liutkus, Antoine and Vincent, Emmanuel},
booktitle={2016 24th European Signal Processing Conference (EUSIPCO)},
pages={1748--1752},
year={2016},
organization={IEEE}
}
@article{liutkus2014kernel,
title={Kernel additive models for source separation},
author={Liutkus, Antoine and Fitzgerald, Derry and Rafii, Zafar and Pardo, Bryan and Daudet, Laurent},
journal={IEEE Transactions on Signal Processing},
volume={62},
number={16},
pages={4298--4310},
year={2014},
publisher={IEEE}
}
[1]:
import nussl
import matplotlib.pyplot as plt
import time
start_time = time.time()
def visualize_and_embed(sources):
plt.figure(figsize=(10, 6))
plt.subplot(211)
nussl.utils.visualize_sources_as_masks(sources,
y_axis='mel', db_cutoff=-40, alpha_amount=2.0)
plt.subplot(212)
nussl.utils.visualize_sources_as_waveform(
sources, show_legend=False)
plt.show()
nussl.play_utils.multitrack(sources)
musdb = nussl.datasets.MUSDB18(
download=True, sample_rate=16000,
strict_sample_rate = False
)
i = 39
item = musdb[i]
mix = item['mix']
[2]:
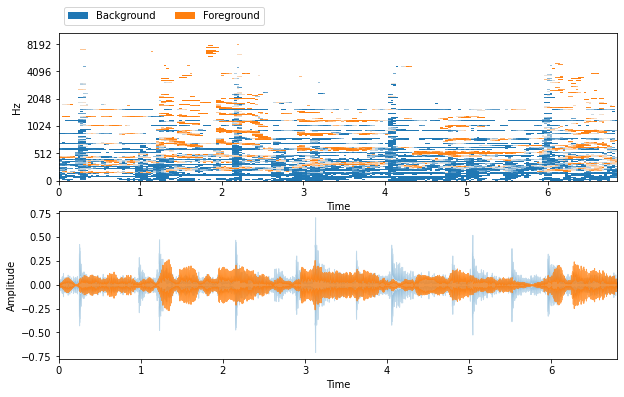
separator = nussl.separation.primitive.Repet(
mix, mask_type='binary')
estimates = separator()
_estimates = {
'Background': estimates[0],
'Foreground': estimates[1]
}
visualize_and_embed(_estimates)
[3]:
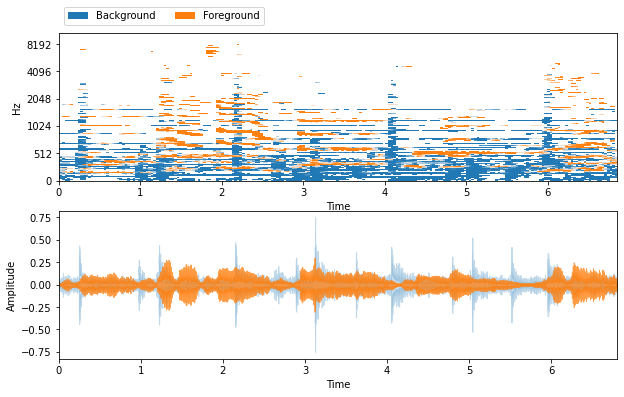
wiener = nussl.separation.benchmark.WienerFilter(
mix, estimates, iterations=10)
estimates = wiener()
estimates = {
'Background': estimates[0],
'Foreground': estimates[1]
}
visualize_and_embed(estimates)
[4]:
end_time = time.time()
time_taken = end_time - start_time
print(f'Time taken: {time_taken:.4f} seconds')
Time taken: 28.8463 seconds