Ensemble Clustering¶
Seetharaman, Prem. Bootstrapping the Learning Process for Computer Audition. Diss. Northwestern University, 2019.
@phdthesis{seetharaman2019bootstrapping,
title={Bootstrapping the Learning Process for Computer Audition},
author={Seetharaman, Prem},
year={2019},
school={Northwestern University}
}
[1]:
import nussl
import matplotlib.pyplot as plt
import time
import warnings
import numpy as np
warnings.filterwarnings("ignore")
start_time = time.time()
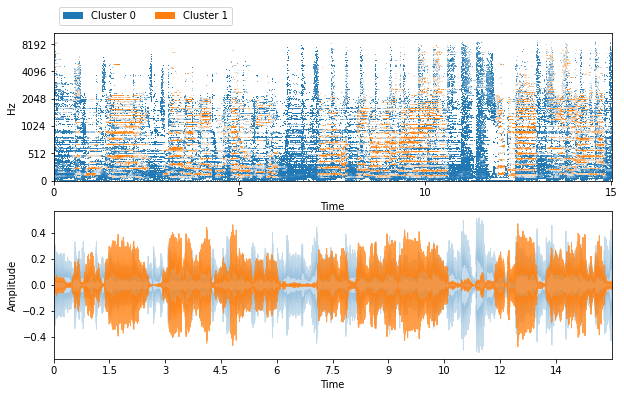
def visualize_and_embed(sources):
plt.figure(figsize=(10, 6))
plt.subplot(211)
nussl.utils.visualize_sources_as_masks(sources,
y_axis='mel', db_cutoff=-40, alpha_amount=2.0)
plt.subplot(212)
nussl.utils.visualize_sources_as_waveform(
sources, show_legend=False)
plt.show()
nussl.play_utils.multitrack(sources)
audio_path = nussl.efz_utils.download_audio_file(
'schoolboy_fascination_excerpt.wav')
audio_signal = nussl.AudioSignal(audio_path)
separators = [
nussl.separation.primitive.FT2D(audio_signal),
nussl.separation.primitive.HPSS(audio_signal),
nussl.separation.primitive.Melodia(audio_signal),
]
weights = [2, 1, 2]
returns = [[1], [0], [1]]
fixed_centers = np.array([
[0 for i in range(sum(weights))],
[1 for i in range(sum(weights))],
])
ensemble = nussl.separation.composite.EnsembleClustering(
audio_signal, 2, separators=separators, init=fixed_centers,
fit_clusterer=False, weights=weights, returns=returns)
ensemble.clusterer.cluster_centers_ = fixed_centers
estimates = ensemble()
estimates = {
f'Cluster {i}': e for i, e in enumerate(estimates)
}
visualize_and_embed(estimates)
Matching file found at /home/pseetharaman/.nussl/audio/schoolboy_fascination_excerpt.wav, skipping download.
[2]:
end_time = time.time()
time_taken = end_time - start_time
print(f'Time taken: {time_taken:.4f} seconds')
Time taken: 19.5243 seconds