Spatial clustering¶
This is a fairly general method. For citations, the following are perhaps a good place to start but by no means is this an exhaustive literature search.
Mandel, Michael I., and Daniel PW Ellis. “EM localization and separation using interaural level and phase cues.” 2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics. IEEE, 2007.
Mandel, Michael I., Daniel P. Ellis, and Tony Jebara. “An EM algorithm for localizing multiple sound sources in reverberant environments.” Advances in neural information processing systems. 2007.
Mandel, Michael I., Ron J. Weiss, and Daniel PW Ellis. “Model-based expectation-maximization source separation and localization.” IEEE Transactions on Audio, Speech, and Language Processing 18.2 (2009): 382-394.
Blandin, Charles, Alexey Ozerov, and Emmanuel Vincent. “Multi-source TDOA estimation in reverberant audio using angular spectra and clustering.” Signal Processing 92.8 (2012): 1950-1960.
Kim, Minje, et al. “Gaussian mixture model for singing voice separation from stereophonic music.” Audio Engineering Society Conference: 43rd International Conference: Audio for Wirelessly Networked Personal Devices. Audio Engineering Society, 2011.
@inproceedings{mandel2007localization,
title={EM localization and separation using interaural level and phase cues},
author={Mandel, Michael I and Ellis, Daniel PW},
booktitle={2007 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics},
pages={275--278},
year={2007},
organization={IEEE}
}
@inproceedings{mandel2007algorithm,
title={An EM algorithm for localizing multiple sound sources in reverberant environments},
author={Mandel, Michael I and Ellis, Daniel P and Jebara, Tony},
booktitle={Advances in neural information processing systems},
pages={953--960},
year={2007}
}
@article{mandel2009model,
title={Model-based expectation-maximization source separation and localization},
author={Mandel, Michael I and Weiss, Ron J and Ellis, Daniel PW},
journal={IEEE Transactions on Audio, Speech, and Language Processing},
volume={18},
number={2},
pages={382--394},
year={2009},
publisher={IEEE}
}
@article{blandin2012multi,
title={Multi-source TDOA estimation in reverberant audio using angular spectra and clustering},
author={Blandin, Charles and Ozerov, Alexey and Vincent, Emmanuel},
journal={Signal Processing},
volume={92},
number={8},
pages={1950--1960},
year={2012},
publisher={Elsevier}
}
@inproceedings{kim2011gaussian,
title={Gaussian mixture model for singing voice separation from stereophonic music},
author={Kim, Minje and Beack, Seungkwon and Choi, Keunwoo and Kang, Kyeongok},
booktitle={Audio Engineering Society Conference: 43rd International Conference: Audio for Wirelessly Networked Personal Devices},
year={2011},
organization={Audio Engineering Society}
}
[1]:
import nussl
import matplotlib.pyplot as plt
import time
import numpy as np
import warnings
warnings.filterwarnings("ignore")
start_time = time.time()
nussl.utils.seed(0)
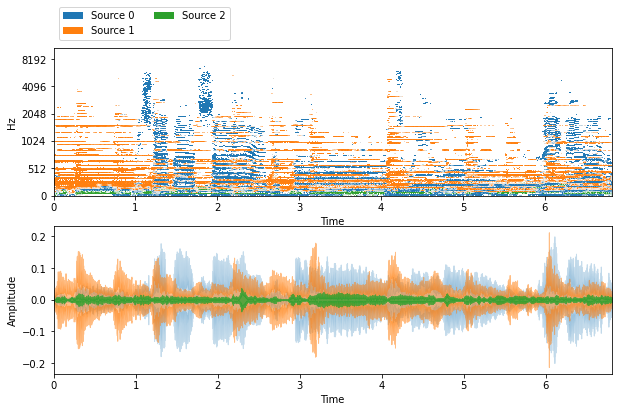
def visualize_and_embed(sources):
plt.figure(figsize=(10, 6))
plt.subplot(211)
nussl.utils.visualize_sources_as_masks(sources,
y_axis='mel', db_cutoff=-40, alpha_amount=2.0)
plt.subplot(212)
nussl.utils.visualize_sources_as_waveform(
sources, show_legend=False)
plt.show()
nussl.play_utils.multitrack(sources)
musdb = nussl.datasets.MUSDB18(download=True)
i = 39
Setting up a signal for SpatialClustering
[2]:
item = musdb[i]
sources = [
item['sources']['other'],
item['sources']['vocals'],
item['sources']['bass']
]
a = nussl.mixing.pan_audio_signal(sources[0], -35)
a_delays = [np.random.randint(1, 20) for _ in range(a.num_channels)]
a = nussl.mixing.delay_audio_signal(a, a_delays)
b = nussl.mixing.pan_audio_signal(sources[1], 0)
b_delays = [np.random.randint(1, 20) for _ in range(b.num_channels)]
b = nussl.mixing.delay_audio_signal(b, b_delays)
c = nussl.mixing.pan_audio_signal(sources[2], 35)
c_delays = [np.random.randint(1, 20) for _ in range(c.num_channels)]
c = nussl.mixing.delay_audio_signal(c, c_delays)
mix = a + b + c
Now running SpatialClustering
[3]:
separator = nussl.separation.spatial.SpatialClustering(
mix, num_sources=3, mask_type='binary')
estimates = separator()
estimates = {
f'Source {i}': e for i, e in enumerate(estimates)
}
visualize_and_embed(estimates)
[4]:
end_time = time.time()
time_taken = end_time - start_time
print(f'Time taken: {time_taken:.4f} seconds')
Time taken: 20.3863 seconds