Deep clustering¶
Hershey, John R., et al. “Deep clustering: Discriminative embeddings for segmentation and separation.” 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
Wang, Zhong-Qiu, Jonathan Le Roux, and John R. Hershey. “Alternative objective functions for deep clustering.” 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
@inproceedings{hershey2016deep,
title={Deep clustering: Discriminative embeddings for segmentation and separation},
author={Hershey, John R and Chen, Zhuo and Le Roux, Jonathan and Watanabe, Shinji},
booktitle={2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={31--35},
year={2016},
organization={IEEE}
}
@inproceedings{wang2018alternative,
title={Alternative objective functions for deep clustering},
author={Wang, Zhong-Qiu and Le Roux, Jonathan and Hershey, John R},
booktitle={2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={686--690},
year={2018},
organization={IEEE}
}
[1]:
import nussl
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings("ignore")
start_time = time.time()
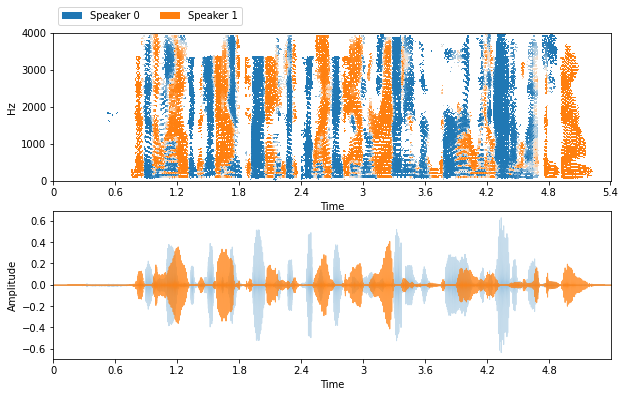
def visualize_and_embed(sources):
plt.figure(figsize=(10, 6))
plt.subplot(211)
nussl.utils.visualize_sources_as_masks(sources,
y_axis='linear', db_cutoff=-40, alpha_amount=2.0)
plt.subplot(212)
nussl.utils.visualize_sources_as_waveform(
sources, show_legend=False)
plt.show()
nussl.play_utils.multitrack(sources)
model_path = nussl.efz_utils.download_trained_model(
'dpcl-wsj2mix-model.pth')
audio_path = nussl.efz_utils.download_audio_file(
'wsj_speech_mixture_ViCfBJj.mp3')
audio_signal = nussl.AudioSignal(audio_path)
separator = nussl.separation.deep.DeepClustering(
audio_signal, 2, model_path=model_path)
estimates = separator()
estimates = {
f'Speaker {i}': e for i, e in enumerate(estimates)
}
visualize_and_embed(estimates)
Matching file found at /home/pseetharaman/.nussl/models/dpcl-wsj2mix-model.pth, skipping download.
Matching file found at /home/pseetharaman/.nussl/audio/wsj_speech_mixture_ViCfBJj.mp3, skipping download.
[2]:
end_time = time.time()
time_taken = end_time - start_time
print(f'Time taken: {time_taken:.4f} seconds')
Time taken: 6.1412 seconds